Building a Live Data Visualization in 4 Days Using Redis Pub/Sub


This post is a story of how we built our Live View feature: first as a hack week project, and then as a first-class feature of Heap. We’ll go into how we used our existing Kafka infrastructure and the powerful but lesser-known Redis pub/sub functionality to make a lightweight event bus. We’ll also explain how we signal and control active Live View sessions, and the steps we took to make this into a production-worthy system.
What is Live View?
Before we get into the details, let’s take a look at Live View itself. In Heap, Live View enables you to view a stream of all raw data coming into your account.
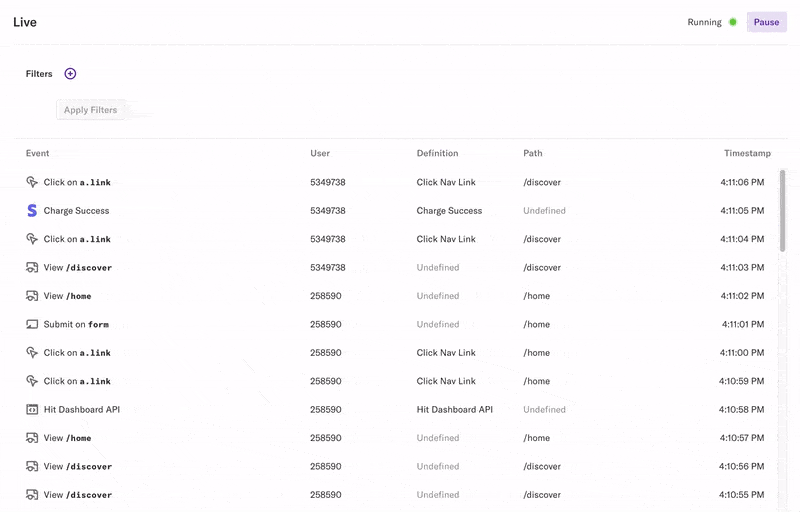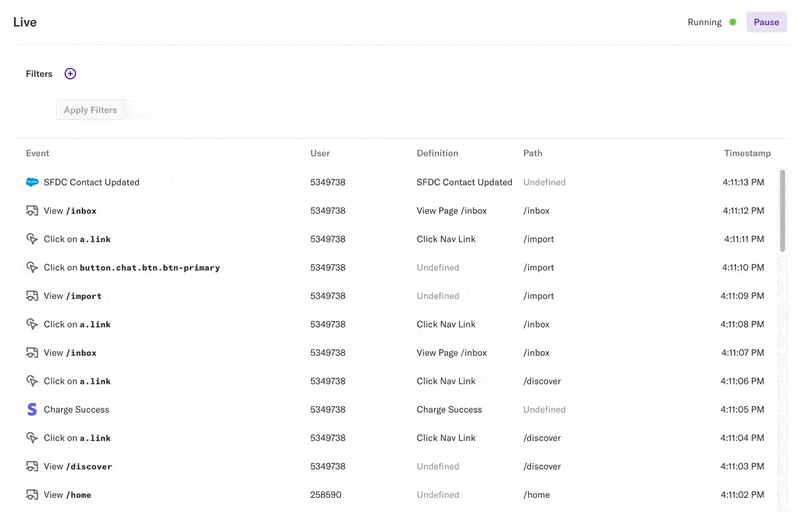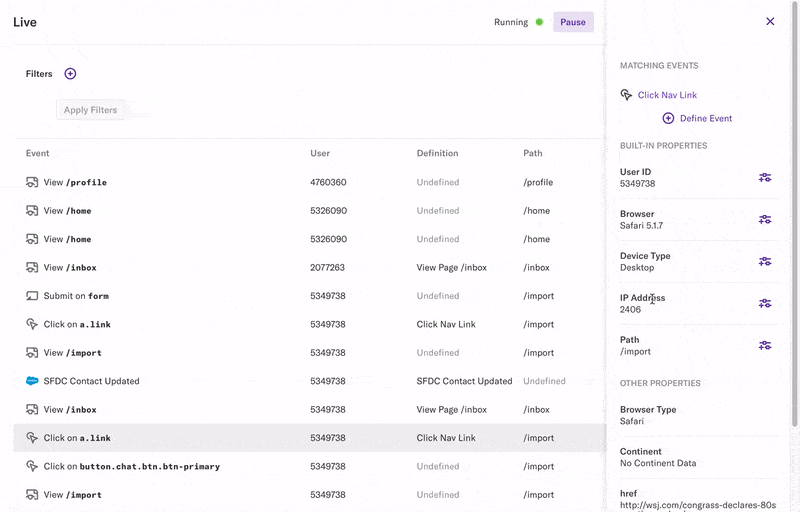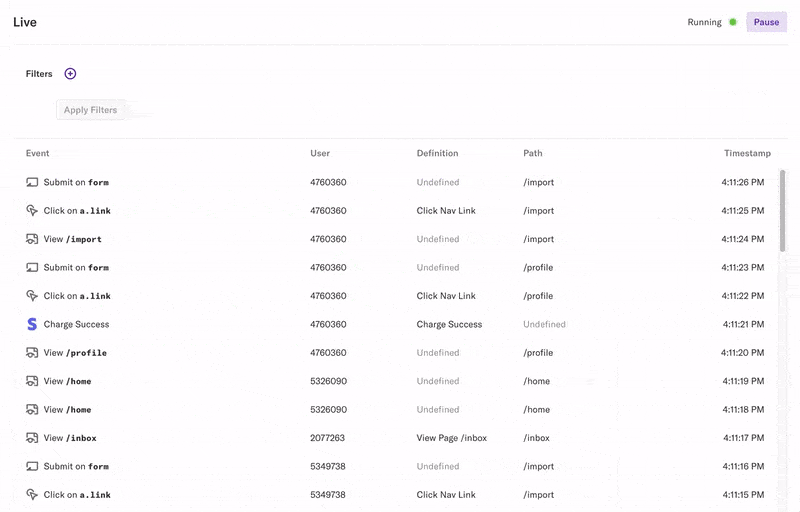
You can filter the stream by properties of the events coming in. For example, you can filter down to just the events on a specific page, or the events involving a specific user. A common customer use case is to filter for yourself as you’re clicking around your product to see the events Heap captures and verify that everything works correctly.
The default view is all data coming into your account, so we rate limit the stream to avoid flooding your browser with thousands of events. This results in a sample of the overall data. With more selective filters, you can see all the matching events.
Live View also has an internal use case. Employees use it when debugging our client-side integrations and giving demos. This was the primary use case before it became a bona fide feature.
Live View v0 – Hack Week
We built the initial version of Live View during our annual hack week. We had roughly 4 days to finish the project, so our solution couldn’t require too much custom infrastructure. We ended up reusing a bunch of components that we already have in place, specifically:
Kafka – All our event data passes through Kafka, so this was the natural data source
Redis – We use Redis liberally throughout our backend as a Swiss army knife ephemeral datastore
Kafka consumer utils – We have a lot of boilerplate code and utils for creating new Kafka consumers
Websockets – they’re great for sending live data down to the browser, and we already use them in part of the product
Using the above, we came up with a high level solution that involved two new infrastructure components:
A new Kafka consumer, which is responsible for keeping track of active Live View sessions, filtering for the relevant events from Kafka, and sending them back to the application.
An ElastiCache (AWS-managed Redis) instance for piping data through.
The interesting stuff is in the details though. Here’s how we use Redis to communicate between the application server and the Kafka consumer.
Using Redis pub/sub to Build Live View
To build Live View, we used pub/sub – a Redis feature that allows Redis to be used as a lightweight event bus. It does all the things we need and we were already familiar with it.
Pub/sub works a little bit differently from the rest of Redis’ features. Rather than manipulating a data structure stored at a specific key, pub/sub allows clients to subscribe to messages published to a given key. When you run publish foo bar, all clients that have previously run subscribe foo will receive the message bar. The publish command itself returns the number of subscribers on the key, which is useful for finding out when there are none left.
We use pub/sub both to control which messages the Kafka consumer sends, and to send the messages themselves. To illustrate how this works, we’ll walk through an end to end example of what happens when a user starts a new Live View session:
Heap user goes to the Live View section of the app and specifies some event filters for the session.
The application server chooses an ephemeral channel key—something like
live_view_channel:<customer id>:<random bytes>—and subscribes to that channel in Redis, listening for events to forward to the frontend.The application signals that a new session has started by publishing a JSON message to the
live\_events\_beginkeyincluding the following fields:
a) customer\_id– the customer the live view session is for.
b) channel – the pub/sub key the kafka consumer should pipe events to.
c) filters – any filters that should be applied to the session (e.g., filter on my user\_id); here we reused a JSON representation for filter predicates that we already use throughout our backend, so we were able to reuse existing library code to perform the filtering.
The Live View Kafka consumer picks up the new session message from
live\_events\_begin, and saves it in a session cache.The Kafka consumer starts forwarding events that match the filters to redis, modulo some rate limiting.
There are a couple of nice things we get out of this design and use of pub/sub:
We don’t need any special logic when a user updates the filters on an existing session. We just resend the session initiation message with updated filters. The Kafka consumer updates the filters for the relevant session and applies them to future messages.
If a session ends, the application server doesn’t have to do anything special to communicate this to the Kafka consumer. It just has to unsubscribe from the channel key. The consumer will learn that the session has ended by monitoring the return value from its
publishcommands. Sincepublishreturns the number of clients subscribed to a channel, we know that when this returns 0 the session has ended, and the consumer can clean its state for that session.

After Hack Week
We managed to pull this system together in a couple of days of development, and the feature worked well. We demoed Live View and it ended up winning an honorable mention. We had deployed it to production behind a hidden URL for the demo.
Before we had a chance to remove it, our customer-facing teams started using it to debug customer implementations and give demos. We decided to keep it in prod, but for internal use only, so we did one final round of cleanup and code review. Live View was “live,” but it wasn’t yet ready to be a customer-facing feature.
Turning Live View Into a Product
After hack week, Live View worked perfectly 99% of the time, but the system had some shortcomings that prevented us from releasing it to customers. Specifically:
If the Live View consumer process died (e.g., the EC2 instance went down), Live View just stopped working.
Deploying changes to the Kafka consumer took down Live View for 3-5 minutes since we needed to restart the single consumer process.
All active session state was lost when restarting the consumer. Active sessions were only kept in memory in the consumer, so they wouldn’t continue after the process restarted.
We had no monitoring or alerting set up, so if any of the above happened we wouldn’t find out until someone complained.
This is what you’d expect out of a one week hack project, but we had to make it solid before we could rely on it to serve our customers.
Preserving Session State
To address these points, we made a couple changes to the system that made it a lot more robust to failure. The first thing we wanted to address was the problem with the consumer losing all session state on restart.
One option would be for the consumer to persist its internal state somewhere on shutdown and load it on startup. However, this requires that shutdowns be intentional, and will lose state when it shuts down uncleanly. There are ways to mitigate this issue, but this solution ends up being a little more complex than we would have liked.
Another option is for the web application server to heartbeat each active session on a short timer. We went with this, because it’s simpler and easier to operate. Every 500 milliseconds, the application server republishes the session initiation message to Redis for all active sessions. If a consumer restarts, it’ll have the metadata for all active sessions within half a second. The consumers effectively re-materialize their internal state on startup based on the stream of session messages from our application servers. This is fine for now, as there are typically less than 100 active Live View sessions at any given time.

Redundant Consumers
With the heartbeating, we were no longer losing session state when the Live View consumer crashed or was restarted. We still needed the feature to be available in case of the consumer stopping, whether from failure or during a deploy.
We extended the system to have multiple consumer machines. At any time, only one of the consumers is active and sending messages to the active sessions. This avoids duplicate events showing up in users’ Live View sessions. We implemented a very simple leader election system using a Redis key with a very short expiry time:
The Kafka consumers continually attempt to acquire the writer lock by setting a key in Redis with their hostname/process id and a very short TTL. We use Redis’ SET NX semantics for this, which ensures a noop if the lock is already held.
Once the lock is acquired, the consumers continually refresh the TTL.
Only the consumer that has the lock is allowed to write events back to the application server. All other consumer operations are identical without the lock, including reading from Kafka and maintaining internal session state.
In this way, only the Kafka consumer with the lock writes events to the application server, and if one of the machines/processes goes down the other process can grab the lock easily.
Combined with the web server heartbeating active sessions twice a second, this solution ensured that both consumers would always have the correct session state internally, and that only one of them would be sending data to the front-end at any given time.
At this point there were two final pieces of the puzzle that needed to fall into place before releasing Live View to customers:
We modified our deploy process to do a rolling restart of of the two Kafka consumers, to ensure there’s always at least one consumer process rolling. Locking transparently handles switchover when the leader is restarted.
We set up monitoring on the whole system. Specifically:
a) We alert on consumer latency, to ensure our customers always see data that’s close to real time.
b) We alert on consumer uptime with a job that mimics the behavior of the application server by starting a Live View session and confirming that messages come through on the correct channel.

What’s Next
Live View has been running smoothly for several months now. We don’t anticipate changes to the core architecture in the near future, but there are a couple of items on the horizon:
Defining virtual events directly from Live View. We’d like to give our customers the ability to create event definitions directly from the Live View UI. It’s a natural place to do it, and a good alternative to our event visualizer.
Scale the Live View consumer to support increased data volume. Right now our data volume is low enough that a single EC2 instance can process all inbound data in real-time; throwing out 99.9% of messages scales nicely in that way! However, we’re eventually going to need to scale the system across multiple instances.
Make the system resilient to Redis downtime. The ElastiCache instance is still a single point of failure in the Live View system. We’re fine with this; we’ve had good experiences with Redis’ reliability, and all data in the instance is ephemeral so we aren’t risking data loss with downtime. However, we could eventually move to a high availability Redis cluster if our risk appetite changes. This would require changing our locking setup to something more advanced, but there are a lot of libraries for this (see Redlock).
Wrapping Up
Live View has turned out to be valuable for both our customers and our employees, but we never would have built it without Hack Week. Hack Week gives engineers the space to build scrappy versions of things they think are cool and then get them in front of the entire company. This allows ideas to flourish that are hard to convey. Sometimes it’s difficult to convince people of the power of an idea in the abstract, but everything clicks once people can see it.
We learned from the demo and the subsequent enthusiastic use that this was a lot more useful than anyone had thought and that it was much easier to build than we might have guessed! This idea was not on anyone’s radar, and now it’s an awesome feature.
If you’re interested in building features like Live View or participating in hack weeks, reach out on Twitter or check out our careers page.